
What is a feature store in machine learning?
To understand feature stores in machine learning, we must first look at the feature engineering process. When developing a predictive model using machine learning or statistical modelling, feature engineering refers to the process of leveraging domain expertise to choose and extract the most important variables from raw data.
The performance of a machine learning model is determined by data pre-processing and data management, so if we design a model without any pre-processing or data handling, the accuracy may suffer. Whereas, if we apply feature engineering to the same model, then the model’s accuracy improves. As a result, feature engineering increases the model’s performance in machine learning.
What is a feature in ML?
A feature is an attribute, or the entire column in the dataset. A feature value refers to a single value of a feature column. To keep the model accurate, features in the feature store are calculated and updated daily.
Why do we need feature stores?
There are a few feature-specific obstacles that feature stores can help data scientists to overcome.
- Reduce duplicate work: Data scientists often spend time developing features that have already been created. Or they don’t have visibility on features developed by other teams which could be used in the project. By using feature stores, data scientists can save time and deploy models more efficiently.
- Consistency between training and production: There is a discrepancy between training and production features as various technologies and programming languages are frequently used. To be effective, a model developed offline in research must make the exact prediction as a model deployed online using the same data. An online and offline feature store implies that given the same input, the model will be fed the same feature in a similar way.
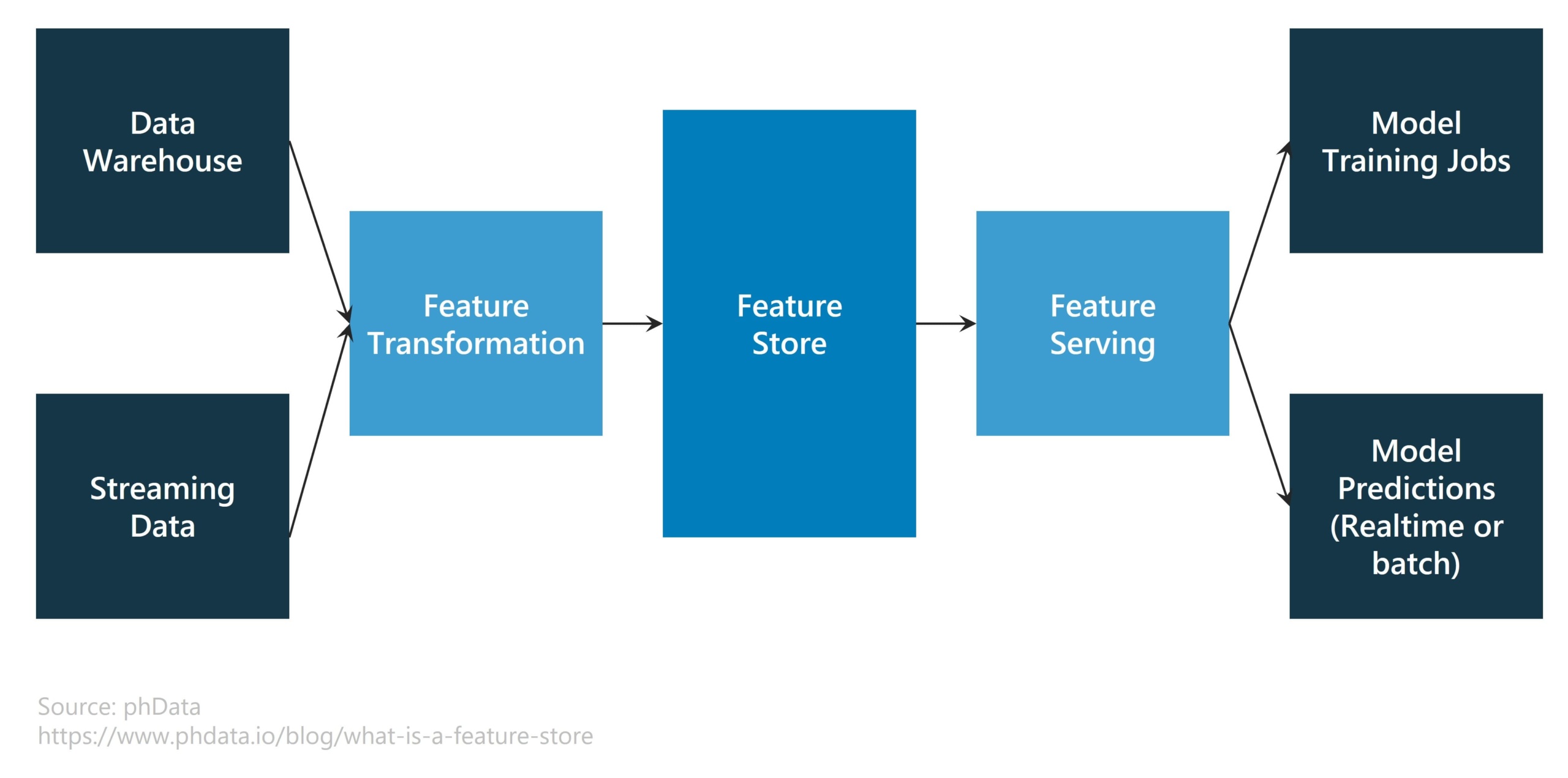
When to use feature stores
A feature store helps fill in the gaps of the MLOps lifecycle by reducing redundant work in development stages and accelerating deployment in production. Without it, organizations and data scientists waste a lot of time generating the same features repeatedly, then validating them for different use cases. This significantly extends the time to market.
Feature stores serve as a central repository for feature data and metadata over the lifecycle of an ML project. A feature store’s data is used for:
- Feature engineering and exploration
- Feature sharing and discovery
- Model training, iteration, and debugging
More precisely, a feature store is a machine learning-specific data system that:
- Executes data pipelines to convert raw data to feature values
- Stores and handles feature data on its own, either online or offline
- Provides consistent feature data for model training and inference
Components of a feature store
A feature store has five main components: storage, transformation, monitoring, serving, and feature registry.
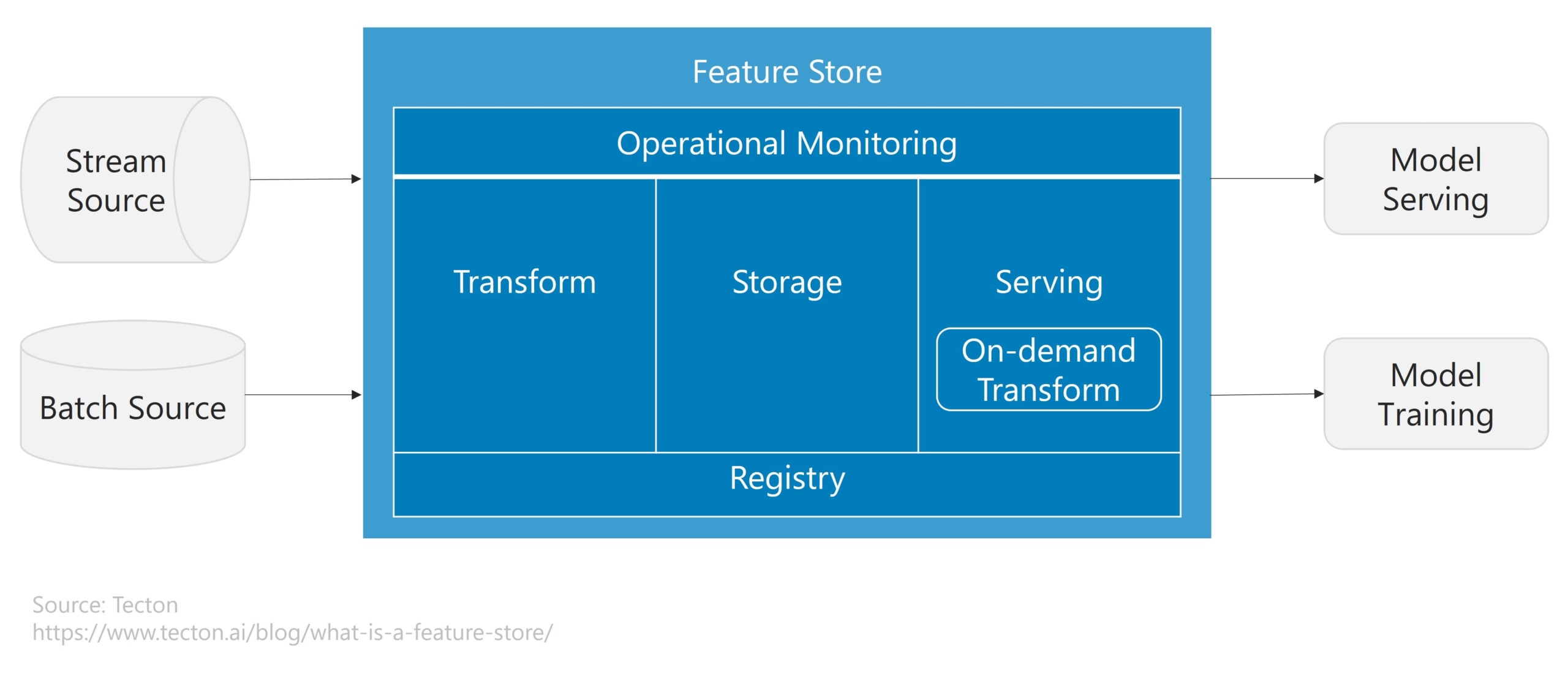
1. Storage
The feature store keeps track of feature data to support retrieval through feature serving layers. They usually include both an online and offline storage layer to accommodate the needs of various feature serving systems.
- Online storage layer usually keeps track of every entity’s most recent feature values. Key-value stores like DynamoDB, Redis, and Cassandra are commonly used to implement them.
- Offline storage layer is generally utilized to store large volumes of feature data for creating and training datasets. Data from offline feature stores are frequently kept in data warehouses or lakes such as Redshift, BigQuery, S3, and Snowflake.
2. Transformation
Transformation handled by the feature store is defined by definitions in a shared feature registry (described below). Feature stores are frequently associated with three different types of data transformations:
- Batch transform is applied to data that is at rest.
- Streaming transform is applied to streaming sources such as Kafka, and PubSub.
- On-demand transform is used to generate features from data that is only available at the prediction moment.
3. Serving
Feature stores serve feature data to models. These models need a persistent view of features throughout training and service.
- For offline serving, Notebook-friendly feature store SDKs are often used to access feature values.
- For online serving, a feature store supplies a single vector of features at a time, made up of the most recent feature values. Responses are delivered via a high-speed API backed by a low-latency database.
4. Monitoring
It’s generally a data issue when something goes wrong in an ML system. Feature stores are distinctly positioned to detect and highlight such issues. They can compute metrics on the features they store and serve that describe accuracy and performance. Feature stores monitor these metrics to provide an indication of an ML application’s overall health.
5. Feature registry
A centralized registry is a critical component in all feature stores of standardized feature definitions and metadata.
- A feature definition is the specification of data transform such as aggregation.
- Metadata is a specific configuration code indicating the feature’s owner, and whether the feature is a production feature (which can be trusted) or an experimental feature (which should be used with caution).
The feature store arranges and configures data transformation, ingestion, and storage based on these definitions and metadata.
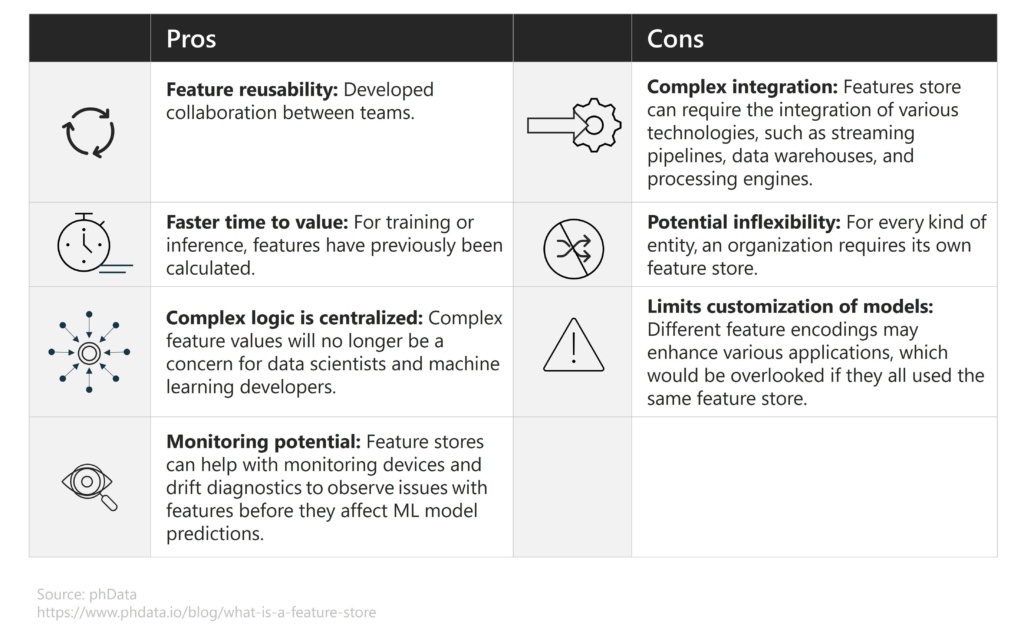
What are the advantages and disadvantages of a feature store?
Feature store tools
There are various competing tools and platforms available in the market like Feast, Tecton, Metaflow, Zipline, and Hopsworks that will help us manage our end-to-end machine learning lifecycle. Each of them comes with some distinct capabilities that cater to a wide range of customers by streamlining their ML workflows.
Let’s look at two popular feature tools that are widely used by organizations helping them build and deploy features reliably and quickly.
1. Feast
Feast is an open-source framework that permits to access data generated by machine learning models. It allows production teams to ingest, serve, register, and monitor features. Feast ensures consistency by controlling and unifying data input from batch and streaming sources.
The process of implementing feast is listed below:
i. Install Feast
-
- pip install feast
ii. Create a feature repository
-
- feast init my_feature_repo
-
- cd my_feature_repo
iii. Register the feature definitions and set up the feature store
-
- feast apply
iv. Explore your data in the web UI (experimental)
-
- feast ui
v. Build a training dataset
vi. Load feature values into your online store
-
- CURRENT_TIME=$(date -u +”%Y-%m-%dT%H:%M:%S”)
- feast materialize-incremental $CURRENT_TIME
vii. Read online features at low latency
2. Tecton
Tecton is a feature-store-as-a-service. Tecton is a fully managed cloud service that can be implemented into a private Virtual Private Cloud (VPC), or a single-tenant SaaS (software as a service) environment provided by Tecton.
The key difference between Tecton and Feast is that Tecton supports transformations, allowing feature pipelines to be managed from start to finish. It orchestrates data pipelines to evaluate and turns raw data into features in real-time.
Comparison between Feast and Tecton

A feature store is a strong tool available for enterprises who want to develop several models based on one or a few entities. The major benefit of the feature store is that it integrates feature transformation logic and enables it to transform new data accordingly and provides examples for model training and online inference.
A feature store can greatly simplify your life if you find yourself repeatedly coding up feature transformations or copying and pasting feature-engineering code from project to project.
Want to learn more about feature stores and improving ML workflows for your business? Contact us to speak to one of our experts.


